月之暗面(kimi)刚刚发布了一篇新论文Attention Residuals 改进了transformer的架构:
原始的attention是序列维度的隐藏态加权平均,用于加权当前时刻前序所有token(含当前token)的信息以生成当前时刻的隐藏态表征用于预测下一token;
而kimi新推出的attention residuals是模型神经网络深度层的加权平均,用于加权混合当前时刻所有深度层的当前token的信息(各深度层的隐藏态表征混合,不再是深度等权)
对比原始的transformer架构,残差连接层的权重默认都是1/n(或者说权重都是1),不是动态加权平均,现在将attention引入残差连接层后实现了深度层的加权平均
2026年上半年agent swarm的发展方向的个人感想
1. CLI即一切 (CLI is All You Need)
- 所有工具都是CLI命令:统一接口,降低复杂度
- 子智能体即子进程:通过命令行调用,隔离执行
- 自然利用Unix生态:管道、重定向、后台执行
2. 并行执行优先 (Parallel Execution First)
- 合适的场景下,子智能体间完全并行:利用Unix并发机制
- 任务级并行:独立任务同时执行
- 资源共享通过文件系统:避免内存共享复杂性
3. 规划驱动工作流 (Planning-Driven Workflow)
- ReAct范式:思考-行动-观察循环
- 自主规划:智能体自主分解任务 ...
重要的事情写在前面!——声明:本文为AI(DeepSeek-R1)创作
(以下是让deepseek-R1以理查德·费曼的风格对大语言模型强化学习中奖励信号观测尺度的演进与思考: 以GRPO为例,探讨 token-level、output-level 到 sentence-level (微观、宏观->中观)奖励设计的渐进式改进这篇博客内容的改写,其用🌰标记新增的费曼式比喻,用🚀标记关键洞见升级)
看的过程中,我的内心,沉默、震惊、兴奋杂糅,久久不能平静,故此特别分享出来。
从微观到宏观,再到中观:大语言模型强化学习中奖励信号观测尺度的演进与思考
——像观察量子世界一样观察语言模型的决策过程
1. 当语言模型遇见强化学习:一场粒子与波动的博弈
...
👀️ 引言: 测试deepseek-R1的思维能力,效果炸裂
声明:以下测试demo均为未人工再修改的原版输出
测试案例:
- 1、让depseek-R1帮我解读两篇博客: 抛砖引玉:浅谈ROPE位置编码模式下,q、k的分布(均值与方差)对注意力远程衰减的影响 再探RoPE(二):为什么RoPE + Bias能在远程衰减和长度外推上发挥重要作用? 并给予第一性原理的解读分析; (具体我是通过将博客原始的markdown格式文本作为上下文,原始的markdown格式文本在博客地址)
- 2、解读完后,让depseek-R1以理查德费曼的方式帮我写成一篇博客文章。
...
对比学习中温度超参应该如何初始化?1/sqrt(d)(方差稳定假设下的一个解析解)
引言
在对比学习(Contrastive Learning)中,温度参数(通常记作 )在损失函数中扮演着关键角色。本文将深入探讨温度参数的作用,并论证其合适的一个初始化方案:(为向量的维度数)。
我们知道,对比学习中的温度参数一般是一个绝对值很低的常数,
比如CLIP模型中设置的为0.07,

Improving Text Embeddings with Large Language Models微软的该论文中设置的为0.02 (CLIP的0.07 和微软的0.02,从数值的数量级上看,也和很接近)

而且A Practitioner’s Guide to Continual Multimodal Pretraining该论文中实证了温度超参对于模型训练过程的效果影响很大;
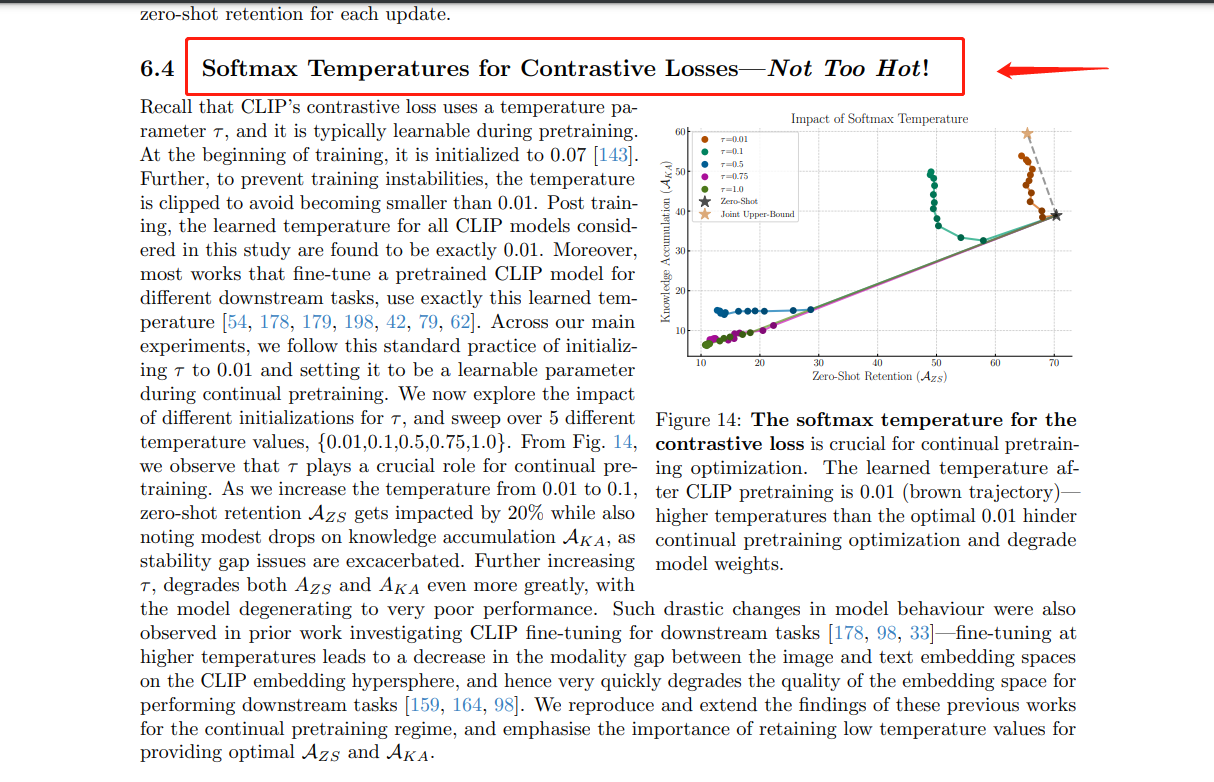 ...
...
reasoning能力微调实战篇:微调qwen基座模型具备思考推理能力(类似o1)
1、引言
关于openai新发布的o1的特性,本篇帖子就不详细介绍了,其底层想法可以阅读这篇论文:Let’s Verify Step by Step。
本次我们的 reasoning能力微调实战的方案如下:
- 数据集:reasoning-base-20k(数据集地址:KingNish/reasoning-base-20k)
- 基座模型:qwen2.5-1.5B (模型地址:Qwen/Qwen2.5-1.5B)
- 微调方法:SFT全参微调;需要特别指出的是微调环节相比标准的sft微调框架(标准的sft微调框架可以参看本人之前的一篇分享:监督式微调(SFT) & 偏好对齐(DPO):From Zero To Hero)虽然整体思路基本一致,但还是需要注意以下差异点:
- 1、需要增加
reasoning这个special token - 2、新增
reasoningspecial token后,还需要同步调整模型的embedding层 - 3、还需同步调整聊天模版(聊天模板的重要性请参阅这篇文章:Chat Templates)
- 4、计算
Loss(损失)的时候,需要综合考虑reasoning + assistant的部分(或者分开单独训练一个reasoning模型+assistant模型也可,本文未单独训练,将reasoning + assistant的损失统一考虑) - 算力资源:google colab的一张A100显卡(方便大家复现)
...